ChatGPT does not browse the internet the way you do. It does not wake up each morning and read the news. Instead, it learned from an enormous collection of text gathered before a specific cutoff date and it uses patterns from that learning to generate responses.
Think of it like this: rather than looking up answers, ChatGPT draws from what it absorbed during training, much like a student who studied extensively and now writes answers from memory during an exam.
Some versions of ChatGPT can also access live web data through tools built into the interface, but even then, the base model relies on pre-trained knowledge. Understanding where that knowledge comes from helps you use ChatGPT more effectively and critically.
How ChatGPT Gets Its Information
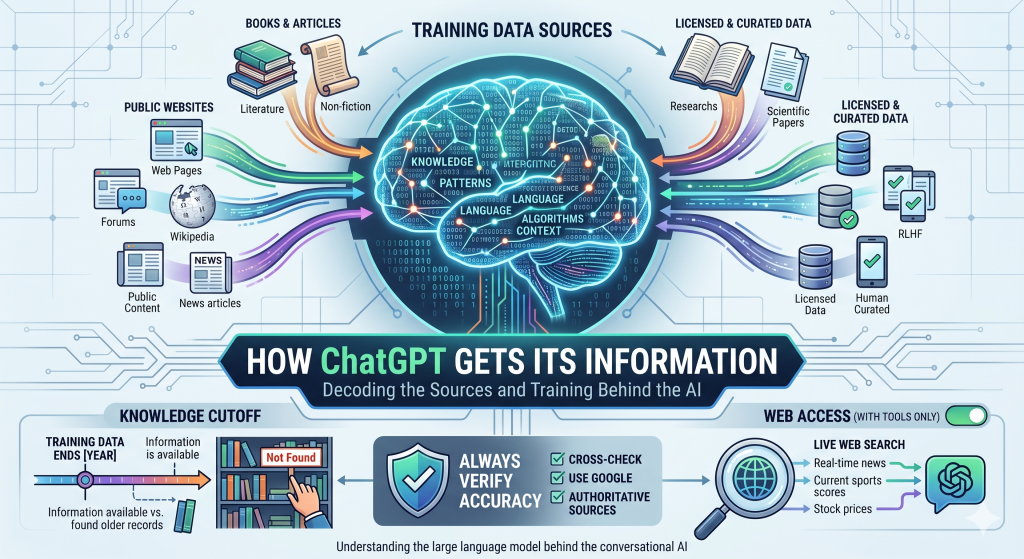
ChatGPT is built on a large language model (LLM) — a type of AI that learns by processing massive amounts of text. During training, the model reads billions of documents, web pages, books, and articles.
It does not memorize facts the way a database does. Instead, it learns patterns — how words relate to each other, how ideas connect, and how language flows in different contexts. When you ask it a question, it generates a response based on those learned patterns.
This is why ChatGPT can discuss almost any topic: cooking, law, science, history, coding. It has seen vast amounts of text on nearly every subject imaginable.
However, it is important to understand that ChatGPT does not “think” or “know” in the human sense. It predicts the most likely next word or phrase based on its training. That distinction matters when evaluating the accuracy of its responses.
What Types of Data Is ChatGPT Trained On?
OpenAI has not published a complete breakdown of every dataset used to train ChatGPT. But based on publicly available information, the training data draws from several broad categories.
Public Websites
A large portion of ChatGPT’s training data comes from the open internet. This includes:
- Educational websites and encyclopedias (such as Wikipedia)
- Blogs, news articles, and opinion pieces
- Technical documentation and developer forums
- Q&A platforms like Stack Overflow and Reddit
- Government and institutional websites
The model was trained on a dataset called WebText and its expanded successors, which captured text from millions of web pages. These sources contributed heavily to ChatGPT’s broad general knowledge.
Books and Articles
Books play a major role in how ChatGPT learned to write and reason. Training data included a large corpus of books covering fiction, non-fiction, science, history, philosophy, and more.
Exposure to long-form written material helped the model understand how arguments are constructed, how narratives flow, and how complex ideas are communicated clearly — skills that directly shape its response quality.
Licensed and Curated Data
Beyond public web content and books, OpenAI also used:
- Licensed datasets from third-party data providers
- Human-curated content reviewed for quality and safety
- Reinforcement Learning from Human Feedback (RLHF) — a process where human trainers ranked responses to shape more helpful, accurate outputs
This curation process is one reason ChatGPT tends to feel more conversational and less random than simply predicting text from raw web data.
Note: The exact composition of OpenAI’s training datasets is not fully public. Avoid accepting specific claims about private data sources without official confirmation.
Does ChatGPT Use the Internet in Real Time?
This is one of the most common questions — and the answer depends on which version you are using.
Standard ChatGPT vs. Web-Enabled Versions
| Version | Internet Access | Data Source |
|---|---|---|
| Base ChatGPT (GPT-4 without tools) | No | Training data only |
| ChatGPT with Browse / Web Search | Yes | Live web + training data |
| ChatGPT plugins or tools | Depends on tool | External APIs and web |
By default, ChatGPT works entirely from its training data. It has no awareness of events that happened after its knowledge cutoff. If you ask it about a news story from last week, it may not know about it — or worse, it may generate a plausible-sounding but incorrect response.
When web search tools are enabled, ChatGPT can retrieve live results to supplement its answers. These results are then incorporated into the response. This significantly improves accuracy for time-sensitive questions.
Why Real-Time Internet Access Matters
Without live web access, ChatGPT cannot tell you:
- Who won last night’s match
- What the current stock price is
- What legislation passed this month
- Breaking news from any source
For questions like these, always use the web-enabled version of ChatGPT — or verify separately using a search engine.
How Often Is ChatGPT Updated?
ChatGPT does not update itself continuously. Training a large language model requires enormous computational resources and time. OpenAI periodically releases new versions (GPT-3.5, GPT-4, GPT-4o, etc.) that incorporate more recent data and improvements.
Each model has a knowledge cutoff — the date after which it has no information. For example, if a model’s cutoff is early 2024, it will not know about events from mid-2024 onward.
This means:
- Older information may appear even when newer data exists
- The model may be unaware of updated research, laws, or public figures
- Some statistics may be outdated without the model signaling this clearly
When accuracy matters — especially for medical, legal, financial, or current events questions — treat ChatGPT’s knowledge cutoff as a hard limitation.
Can ChatGPT Access Private Information?
No. ChatGPT does not have access to your private files, emails, banking records, medical history, or any personal data unless you directly share it within the conversation.
Here is a clear breakdown:
- Public information: ChatGPT may know about you if information about you exists in publicly indexed web pages, books, or news articles from before its training cutoff.
- Private information: It has no access to private accounts, databases, or personal records.
- Conversation content: What you type in a ChatGPT session may be used by OpenAI to improve future models, depending on your privacy settings. You can opt out of this in your account settings.
Never share sensitive personal information — passwords, financial details, medical records — in a ChatGPT conversation.
Is ChatGPT Always Accurate?
No. ChatGPT is often impressive, but it makes mistakes. Understanding why helps you use it more safely.
Why ChatGPT Sometimes Gives Wrong Answers
Hallucinations are the most well-known issue. This is when ChatGPT generates confident-sounding statements that are factually incorrect. It may cite non-existent studies, invent quotes from real people, or describe events that never happened.
Other common reasons for inaccuracy:
- Outdated information: The training data has a cutoff, and the world changes.
- Misinterpreted prompts: Ambiguous questions can lead to off-target answers.
- Incomplete context: Without full background, ChatGPT fills gaps with assumptions.
- Training data bias: If the training data contained errors or biases, those may surface in responses.
How to Verify ChatGPT Information
Follow these practical steps before acting on any ChatGPT response:
- Cross-check with authoritative sources — government sites, academic journals, established news outlets.
- Search independently — use Google or Bing to confirm key claims.
- Ask for sources — ChatGPT can sometimes point to sources (though not always accurately).
- Be especially cautious with medical, legal, and financial information.
- Check the date — if something may have changed since the knowledge cutoff, verify it.
How ChatGPT Differs From Google Search
Many people use ChatGPT and Google interchangeably, but they work very differently.
| Feature | ChatGPT | Google Search |
|---|---|---|
| How it works | Generates text from training | Retrieves and ranks existing web pages |
| Real-time info | Only with tools enabled | Yes, always |
| Response format | Conversational answers | Links and snippets |
| Source visibility | Often none | Links provided |
| Best for | Explaining, writing, brainstorming | Finding specific pages, current info |
| Accuracy risk | Can hallucinate | Shows real pages (may have unreliable sources) |
Google retrieves what exists on the web. ChatGPT synthesizes an answer from what it learned. One surfaces sources; the other generates a response. For current events and fact-checking, Google is more reliable. For explanation, writing help, and analysis, ChatGPT often excels.
Does ChatGPT Learn From User Conversations?
This is a nuanced question. ChatGPT does not learn in real time from individual conversations. A response you receive today does not instantly update the model’s knowledge for the next user.
However, OpenAI may use conversation data to train future model versions, subject to its privacy policy. This is how many AI systems improve over time — through aggregate learning from large volumes of interactions.
What this means for users:
- Your specific conversation will not change ChatGPT’s behavior for other users immediately.
- If you share sensitive or personal information, OpenAI may have access to it depending on your settings.
- You can turn off chat history or opt out of training data use in your ChatGPT account settings.
Common Misconceptions About ChatGPT Information
“ChatGPT knows everything”
It does not. Its knowledge is limited to its training data, which has a cutoff date. It has no awareness of events after that date without live tools.
“ChatGPT thinks like a human”
It does not think or reason the way humans do. It predicts statistically likely responses based on patterns in its training data. It has no consciousness, emotions, or genuine understanding.
“ChatGPT always uses live internet data”
Only if the web browsing feature is enabled. Without it, ChatGPT works entirely from pre-trained knowledge.
“ChatGPT understands information perfectly”
It generates plausible text — not guaranteed truth. It can misunderstand questions, miss nuance, and produce confident but incorrect answers.
Frequently Asked Questions
Where does ChatGPT get its answers from?
ChatGPT generates answers from patterns learned during training on a large dataset of text from the internet, books, and other sources. It does not look up answers in real time unless a web search tool is enabled.
Does ChatGPT use Google for answers?
No. ChatGPT does not use Google to generate responses by default. It draws from its own training data. Some versions include a separate web search tool that can retrieve live results, but this is distinct from how Google works.
Does ChatGPT access the internet?
Standard ChatGPT does not access the internet. Versions with browsing tools enabled can retrieve live web pages to supplement answers.
Is ChatGPT trained on books and websites?
Yes. ChatGPT’s training data includes a large volume of publicly available web content, books, articles, and curated datasets.
Can ChatGPT give false information?
Yes. ChatGPT can generate inaccurate, outdated, or fabricated information — a phenomenon called hallucination. Always verify important information from authoritative sources.
Conclusion
ChatGPT gets its information from a massive training process, not from live internet browsing. It learned from billions of documents — websites, books, articles, and curated datasets — and uses that knowledge to generate responses.
It is powerful, but it is not infallible. Its knowledge has a cutoff, it can hallucinate, and it works best when you treat it as a knowledgeable assistant rather than an absolute authority.
For time-sensitive or high-stakes questions, use the web-enabled version of ChatGPT or verify answers independently. The more you understand how ChatGPT gets its information, the more effectively — and safely — you can use it.